tesseract.js是流行的面向纯Javascript的OCR引擎的。该库支持100多种语言(中文支持)
tesseract-ocr下载安装及python里调用
win+r >> 窗口输入cmd >> 输入 pip install pytesseract 第二种: win+r >> 窗口输入cmd >> 输入 pip install pytesseract -i https://pypi.tuna.tsinghua.edu.cn/simple

第一步,用git下载gitbug里的tesseract.js
git clone https://github.com/naptha/tesseract.js.git
第二步,进入目录
cd tesseract.js
第三步,安装依赖
npm install
可以换 cnpm install 来安装,cnpm为国内的npm,速度更多,更多帮助
第四步,运行tesseract.js,生成服务器来调试
npm start
第五步,浏览器里输入网址 http://127.0.0.1:3000/examples/browser/basic-efficient.html
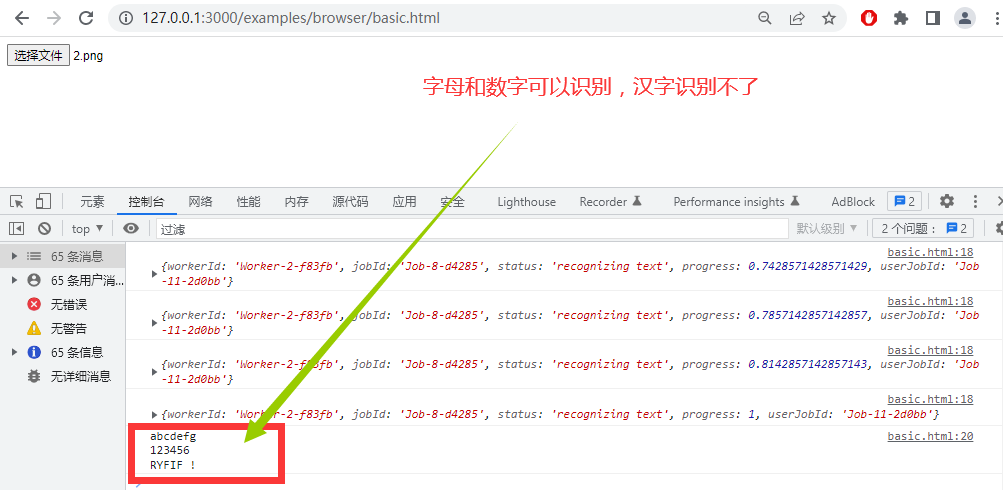
上传一个图片,图片要以字母和数字组成。稍等一会,在浏览器的调试面板里可以看到输出的结果了。
上传的图片
 识别图片
识别图片
第一步,下载地址
https://github.com/tesseract-ocr/tesseract
第二步,选择版本
https://tesseract-ocr.github.io/tessdoc/Installation.html
第三步,下载版本
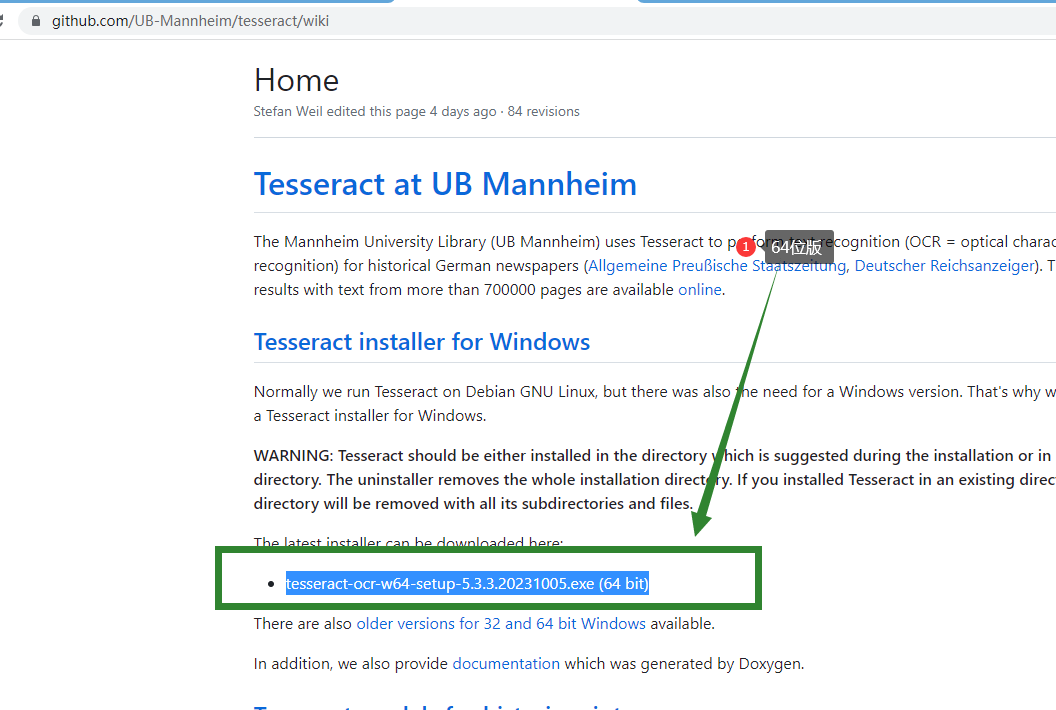
https://github.com/UB-Mannheim/tesseract/wiki
第一步,下载地址
 第二步,选择版本
第二步,选择版本
 第三步,下载版本
第三步,下载版本
 第四步,双击安装 >> next
第四步,双击安装 >> next
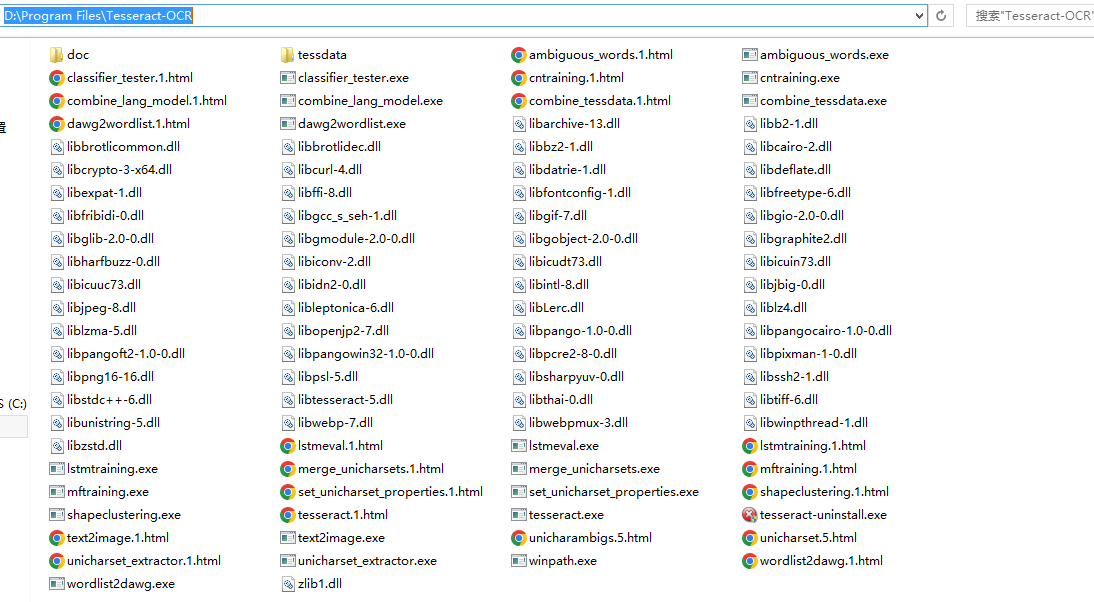
 第五步,Tesseract-OCR 目录结构
第五步,Tesseract-OCR 目录结构
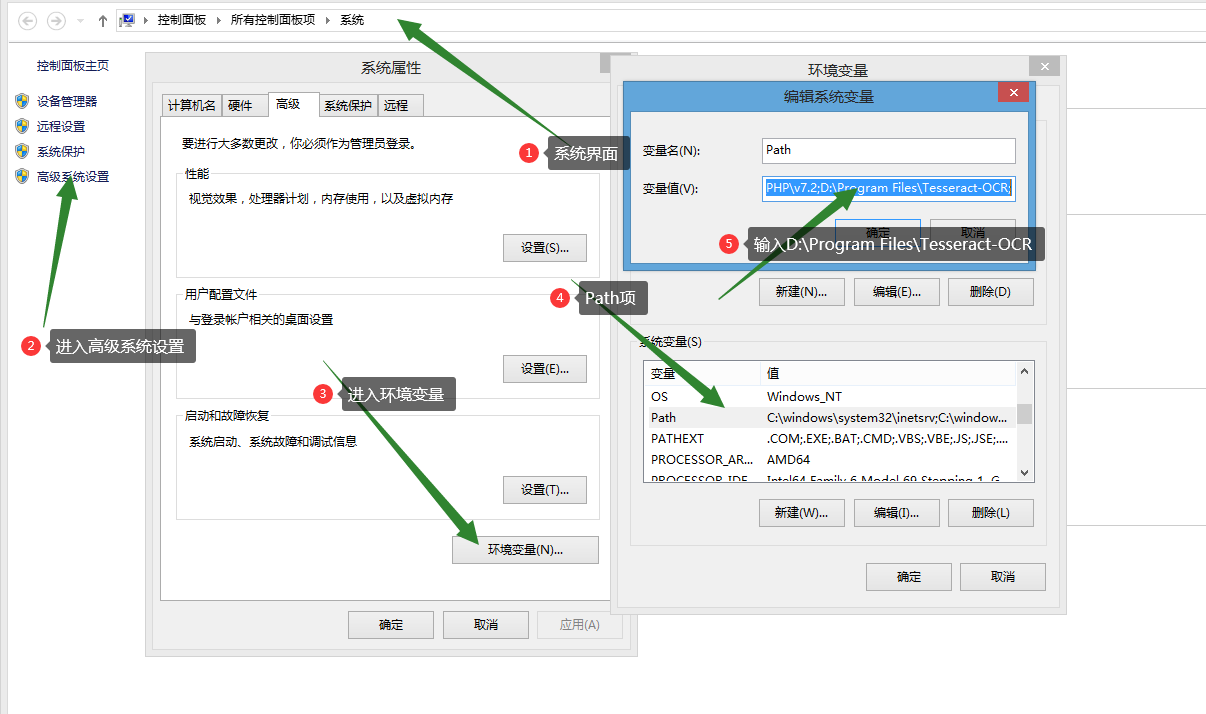
 第六步,D:\Program Files\Tesseract-OCR 目录 添加到系统环境里
第六步,D:\Program Files\Tesseract-OCR 目录 添加到系统环境里
 第七步,cmd里输入>> tesseract D:\work\xiyueta\article\images\tesseractjs\atemp.png stdout
第七步,cmd里输入>> tesseract D:\work\xiyueta\article\images\tesseractjs\atemp.png stdout
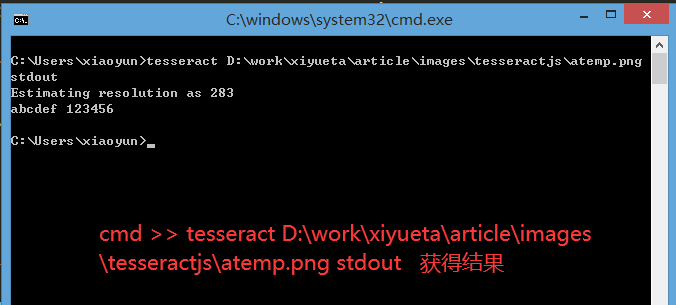 已有的训练数据集可使用命令“tesseract --list-langs”查看
已有的训练数据集可使用命令“tesseract --list-langs”查看
https://github.com/tesseract-ocr/tessdata_best 下载更多字体
git clone git@github.com:tesseract-ocr/tessdata_best.git
tesseract D:\work\xiyueta\article\images\tesseractjs\cn1.png stdout -l chi_sim 指定中文字体
pothon里使用pytesseract图片识别转文字
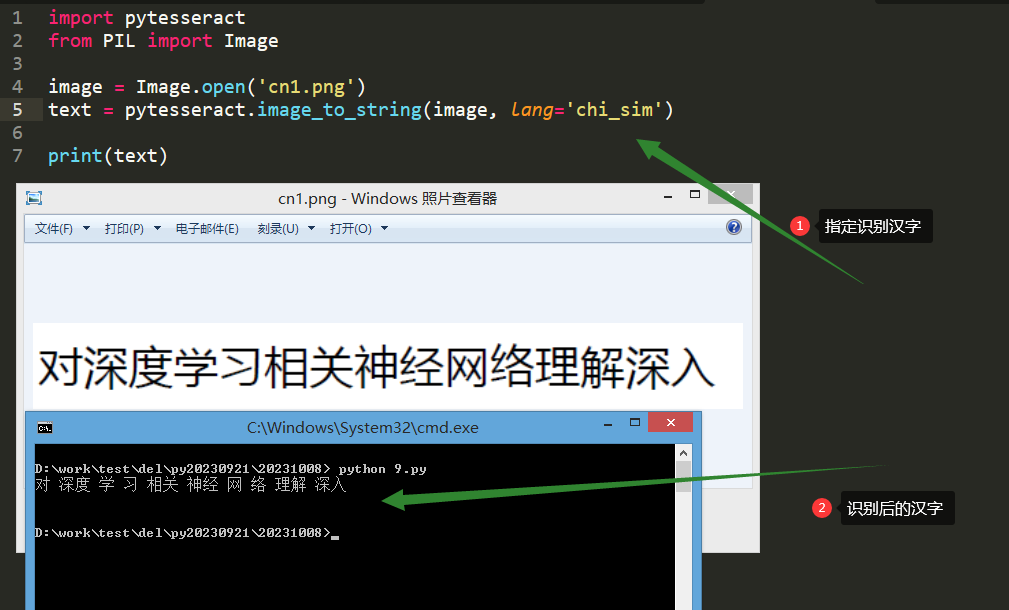
import pytesseract
from PIL import Image
image = Image.open('cn1.png')
text = pytesseract.image_to_string(image, lang='chi_sim')
print(text)