Python是一种流行的高级编程语言,它有着简单易学的语法和丰富的标准库,可以用于开发各种类型的应用程序,包括Web应用、桌面应用程序、数据分析、图像处理、人工智能和机器学习等。Python是一种解释性语言,意味着它可以在不进行编译的情况下直接运行程序。它还具有可拓展性,可以集成其他语言,如C或Java等,以提高执行速度。Python社区非常强大,有很多开源工具和库,可以为开发人员提供更简便的解决方案。

在浏览器中输入: https://www.python.org/downloads/windows/ >> 选择 Python 3.10.11 - April 5, 2023
查看python版本 cmd >> python --version
查看所有已安装模块 cmd >> pip list
如果安装不了,试试 python-3.9.1-amd64.exe

双击进入安装界面

全部选中
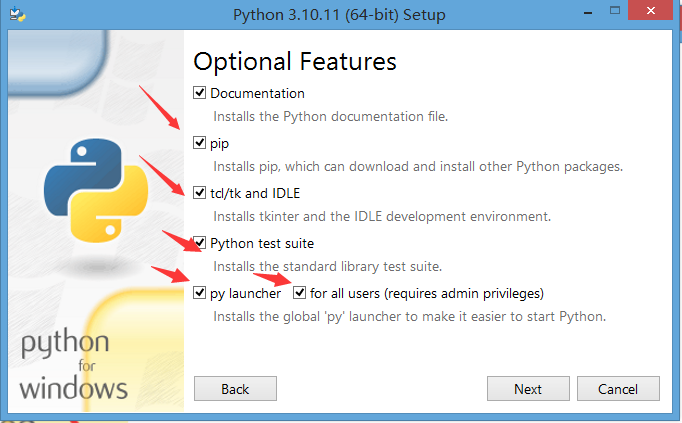
选中 precompile standard library 预编译标准库

在Windows操作系统中,在命令提示符(cmd)中输入以下命令可以查看Python版本号:
python --version

pytorch安装 打开网站 https://pytorch.org/get-started/locally/
选择配置结果为: pip3 install torch torchvision torchaudio
更换pip3源 pip install -i https://mirrors.aliyun.com/pypi/simple/ torch torchvision torchaudio
【pytorch使用教程】
图片模糊转清晰,失败了

cmd输入 git clone https://github.com/sczhou/CodeFormer >> 完成后输入 >> cd CodeFormer 进入目录
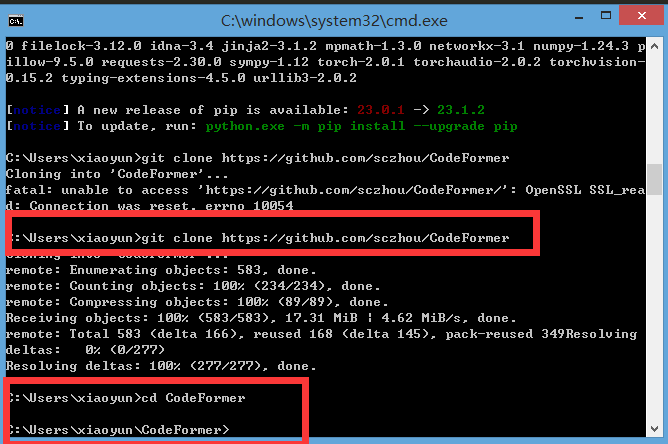
cmd输入 pip install -r requirements.txt -q
更换pip3源 pip3 install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements.txt -q

cmd输入 pip3 install -i https://mirrors.aliyun.com/pypi/simple/ -q gradio
cmd输入 python basicsr/setup.py develop


下载预训练模型:python scripts/download_pretrained_models.py facelib
第二个模型: python scripts/download_pretrained_models.py CodeFormer

面部修复(裁剪和对齐的面部) python inference_inpainting.py --input_path C:\Users\xiaoyun\CodeFormer\inputs\gray_faces
python安装时出错,提示0x80070643
换版本,如:Python 3.9.10 - Jan. 14, 2022 试试

OpenCV是一个开源的计算机视觉库,提供了丰富的图像处理和计算机视觉算法,以及易于使用的API,支持C++、Python等多种编程语言,可以在Linux、Windows和Mac OS等多个操作系统上运行。
win+r >> 窗口输入cmd >> 输入 pip install opencv-python
第二种: win+r >> 窗口输入cmd >> 输入 pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
查看版本号及路径:
import cv2
print("cv2版本号=" + cv2.__version__)
print("cv2路径=" + cv2.__file__)

import cv2
img = cv2.imread('2.png')
qrcode=cv2.QRCodeDetector()
result,points,code = qrcode.detectAndDecode(img)
qrcode.detectAndDecode(img)
print(result)
print(points)
print(code)
# opencv 计算机视觉
import cv2
import numpy as np
if __name__ == '__main__':
rose = cv2.imread('./mgh.png') # 图片 有中文读取不了
# print(rose.shape) # (100 200 3) 数组形状 100像素
# print(type(rose)) # numpy数组
# print(rose) # 三个[三维数组 (彩色图片:高度、宽度、像素红绿蓝)]
cv2.imshow('rose',rose) # 弹出窗口 窗口名称有中文会乱码
cv2.waitKey() #等待键盘输入,任意输入,出发这个代码窗口消失
cv2.destroyAllWindows() # 销毁内存
opencv-contrib-python是指OpenCV的贡献模块。它包含了一些不属于核心OpenCV库的功能和算法,以及社区中其他人编写的一些实验性代码和增强功能。
win+r >> 窗口输入cmd >> 输入 pip install opencv-contrib-python
第二种: win+r >> 窗口输入cmd >> 输入 pip install opencv-contrib-python -i https://pypi.tuna.tsinghua.edu.cn/simple
指定版本: win+r >> 窗口输入cmd >> 输入 pip install opencv-contrib-python==3.4.2.16 -i https://pypi.tuna.tsinghua.edu.cn/simple --user
安装更全更完整版,输入网址:https://opencv.org/


jieba是一个中文分词的库,可以帮助我们把中文文本切分成一个个词语,便于后续的自然语言处理工作。jieba是基于词频算法和统计方法的分词库,而不是基于字典匹配的,所以能够处理很多新词和未登录词等。案例代码
github网址:https://github.com/fxsjy/jieba
win+r >> 窗口输入cmd >> 输入 pip install jieba
第二种: win+r >> 窗口输入cmd >> 输入 pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple
PaddlePaddle Tiny是百度推出的一款基于PaddlePaddle框架的轻量级深度学习推理引擎,Windows操作系统安装不了
pip install paddlepaddle-tiny==1.6.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
import jieba
import jieba
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("全模式: " + "/ ".join(seg_list)) # 全模式
print("-----------")
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("精确模式: " + "/ ".join(seg_list)) # 精确模式
print("-----------")
seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式
print("默认是精确模式:"+ ", ".join(seg_list))
print("-----------")
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print("搜索引擎模式:"+ ", ".join(seg_list))
print("")
# 精确模式分词
words = jieba.cut("今天天气真好,我们一起去外面走走吧!", cut_all=False)
# 把分词结果转化成列表
word_list = list(words)
# 输出分词结果
print(word_list)
#输入结果 ['今天天气', '真', '好', ',', '我们', '一起', '去', '外面', '走走', '吧', '!']
gensim是一个开源的自然语言处理库,提供了许多常用的NLP功能,例如文本处理、语言模型、主题建模、相似度计算等等。gensim的核心算法实现都是用Python完成的,能够轻松地处理大规模的文本数据。案例代码
github网址:https://github.com/RaRe-Technologies/gensim
win+r >> 窗口输入cmd >> 输入 pip install gensim
第二种: win+r >> 窗口输入cmd >> 输入 pip install gensim -i https://pypi.tuna.tsinghua.edu.cn/simple
from gensim.models import Word2Vec
# 文本数据
sentences = [["cat", "say", "meow"], ["dog", "say", "woof"]]
# 训练模型
model = Word2Vec(sentences, min_count=1)
# 获取词向量
vector = model.wv["cat"]
# 打印词向量
print(vector)
'''
输入结果
[-0.00713902 0.00124103 -0.00717672 -0.00224462 0.0037193 0.00583312
0.00119818 0.00210273 -0.00411039 0.00722533 -0.00630704 0.00464722
-0.00821997 0.00203647 -0.00497705 -0.00424769 -0.00310898 0.00565521
0.0057984 -0.00497465 0.00077333 -0.00849578 0.00780981 0.00925729
-0.00274233 0.00080022 0.00074665 0.00547788 -0.00860608 0.00058446
0.00686942 0.00223159 0.00112468 -0.00932216 0.00848237 -0.00626413
-0.00299237 0.00349379 -0.00077263 0.00141129 0.00178199 -0.0068289
-0.00972481 0.00904058 0.00619805 -0.00691293 0.00340348 0.00020606
0.00475375 -0.00711994 0.00402695 0.00434743 0.00995737 -0.00447374
-0.00138926 -0.00731732 -0.00969783 -0.00908026 -0.00102275 -0.00650329
0.00484973 -0.00616403 0.00251919 0.00073944 -0.00339215 -0.00097922
0.00997913 0.00914589 -0.00446183 0.00908303 -0.00564176 0.00593092
-0.00309722 0.00343175 0.00301723 0.00690046 -0.00237388 0.00877504
0.00758943 -0.00954765 -0.00800821 -0.0076379 0.00292326 -0.00279472
-0.00692952 -0.00812826 0.00830918 0.00199049 -0.00932802 -0.00479272
0.00313674 -0.00471321 0.00528084 -0.00423344 0.0026418 -0.00804569
0.00620989 0.00481889 0.00078719 0.00301345]
'''
scikit-learn是一个基于Python的机器学习库,提供了许多常用的机器学习算法和工具,例如分类、回归、聚类、降维、模型选择等等。scikit-learn还提供了许多用于数据预处理和特征工程的工具,可用于数据清洗、缩放、编码等操作。官网:https://scikit-learn.org/stable/案例代码
win+r >> 窗口输入cmd >> 输入 pip install scikit-learn
第二种: win+r >> 窗口输入cmd >> 输入 pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=0)
# 训练模型
cls = SVC(kernel='linear')
cls.fit(X_train, y_train)
# 预测
y_pred = cls.predict(X_test)
# 计算准确率
acc = accuracy_score(y_test, y_pred)
# 输出结果
print("准确率:", acc)
#输入结果 准确率: 0.9777777777777777
pyttsx3是将文本转换成语音案例代码
win+r >> 窗口输入cmd >> 输入 pip install pyttsx3
第二种: win+r >> 窗口输入cmd >> 输入 pip install pyttsx3 -i https://pypi.tuna.tsinghua.edu.cn/simple
import pyttsx3
# 创建一个TTS引擎
engine = pyttsx3.init()
engine.say("你好")
engine.runAndWait()
Natural Language Toolkit(NLTK)是一个用于处理人类语言数据的Python库。网址 http://nltk.org/
win+r >> 窗口输入cmd >> 输入 pip install nltk
第二种: win+r >> 窗口输入cmd >> 输入 pip install nltk -i https://pypi.tuna.tsinghua.edu.cn/simple
手动下载 punkt 放到 C:\Users\xiaoyun\nltk_data\tokenizers 目录里
打开网址 >> https://github.com/nltk/nltk_data/tree/gh-pages/packages/tokenizers 下载这两个文件
C:\Users\xiaoyun\nltk_data\tokenizers 目录 需要手动创建 nltk_data\tokenizers 目录

from nltk import word_tokenize
s="this is xiaomin"
print(s)
s2=word_tokenize(s)
print(s2)
#输出结果
#this is xiaomin
#['this', 'is', 'xiaomin']
ChatterBot 是基于 Python 的开源对话引擎,能通过机器学习自动生成回答并持续进化。
win+r >> 窗口输入cmd >> 输入 pip install chatterbot
第二种: win+r >> 窗口输入cmd >> 输入 pip install chatterbot -i https://pypi.tuna.tsinghua.edu.cn/simple
查看案例>>

from chatterbot import ChatBot
from chatterbot.trainers import ListTrainer
# 第一步:初始化机器人
# 指定存储方式为 SQLStorageAdapter,它会自动生成一个 SQLite 数据库文件
my_bot = ChatBot(
"XiaoZhushou",
storage_adapter='chatterbot.storage.SQLStorageAdapter',
logic_adapters=[
'chatterbot.logic.BestMatch', # 最佳匹配逻辑
'chatterbot.logic.TimeLogicAdapter' # 能回答时间的逻辑
],
database_uri='sqlite:///database.db'
)
# 第二步:准备训练数据
# 这是一个列表,机器人会按顺序学习“问”与“答”
conversation = [
"你好",
"你好呀!今天心情怎么样?",
"我今天心情不太好",
"怎么了?谁惹我家小朋友不开心了?说出来让我哄哄你。",
"工作太累了",
"辛苦啦,抱抱你。等下忙完去吃顿好的奖励自己,好吗?"
]
# 第三步:开始训练
trainer = ListTrainer(my_bot)
trainer.train(conversation)
# 第四步:进行对话测试
print("机器人已就绪,输入 'exit' 退出对话。")
while True:
try:
user_input = input("你:")
if user_input.lower() == 'exit':
break
# 获取回复
bot_response = my_bot.get_response(user_input)
print(f"机器人:{bot_response}")
except (KeyboardInterrupt, EOFError, SystemExit):
break
pip install pillow
Pillow 是 PIL 的替代版本,PIL 软件包提供了基本的图像处理功能,如:改变图像大小,旋转图像,图像格式转换,色场空间转换,图像增强,直方图处理,插值和滤波等等
第二种: win+r >> 窗口输入cmd >> 输入 pip install pillow -i https://pypi.tuna.tsinghua.edu.cn/simple
查看pillow版本号:pip show pillow
pip install Flask
Flask 是一个基于 Python 的轻量级 Web 应用框架。它使用 Werkzeug 作为 HTTP 工具包和 Jinja 2 作为模板引擎。
第二种: win+r >> 窗口输入cmd >> 输入 pip install Flask -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install parsel
是一个用于数据抽取和爬虫的 Python 库。它是基于 lxml 库开发的,提供了众多的解析和选择器工具,为 Python 爬虫提供了便利。
第二种: win+r >> 窗口输入cmd >> 输入 pip install parsel -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install chardet
chardet 是一个用于字符编码检测的 Python 库,可以自动检测文本、字节流的编码格式,而无需手动指定。它可以处理多种编码格式,包括 ASCII、UTF-8、UTF-16、GB2312 等等。当我们需要对一些从未见过的文本进行解码时,使用 chardet 就可以很方便地检测文本的编码格式。
第二种: win+r >> 窗口输入cmd >> 输入 pip install chardet -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install selenium==3.141.0 <指定版本安装>
selenium 是浏览器自动化操作 第二种: win+r >> 窗口输入cmd >> 输入 pip install selenium==3.141.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
安装更全更完整版,输入网址:https://opencv.org/
主要获得里面的人脸识别训练 opencv\sources\data\haarcascades\haarcascade_frontalface_alt2.xml
查看python下OpenCV版本的方法,在cmd里输入:
python -c "import cv2; print(cv2.__version__)"
进入opencv官方下载人脸识别库https://opencv.org/releases/ 下载 opencv-4.8.0-windows.exe
运行解压,进入目录
opencv\sources\data\haarcascades
需要安装的库有:
pip install pillow,opencv-python,opencv-contrib-python -i https://pypi.tuna.tsinghua.edu.cn/simple


案例1,读取图片,显示图片
如果出现缺少.face时,卸载opencv-python和opencv-contrib-python,再重新安装
pip uninstall opencv-python
pip uninstall opencv-contrib-python
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install opencv-contrib-python -i https://pypi.tuna.tsinghua.edu.cn/simple

#导入cv模块
import cv2 as cv
#读取图片
img = cv.imread('face1.jpg') #注意读取图片的路径及图片名不能有中文,不然数据读取不出来
#显示图片
cv.imshow('read_img',img)
#等待键盘的输入 单位是毫秒 传入 0 无限等待
cv.waitKey(0)
#释放内存 由于OpenCV底层是C++语言编写的 使用完内存必须释放
cv.destroyAllWindows()
案例2,灰度转换

#导入cv模块
import cv2 as cv
#读取图片
img = cv.imread('face1.jpg')
#灰度转换
gray_img = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
# gray_img = cv.cvtColor(img,cv.COLOR_RGB2BGR) #另一种颜色
#显示灰度
cv.imshow('gray_img',gray_img)
#保存灰度图片
cv.imwrite('gray_face1.jpg',gray_img)
#显示图片
cv.imshow('read_img',img)
#等待键盘的输入 单位是毫秒 传入 0 无限等待
cv.waitKey(0)
#释放内存 由于OpenCV底层是C++语言编写的 使用完内存必须释放
cv.destroyAllWindows()
案例3,裁切图片

#导入cv模块
import cv2 as cv
#读取图片
img = cv.imread('face1.jpg')
#修改尺寸
resize_img = cv.resize(img,dsize=(200,200))
#显示原图
cv.imshow('img',img)
#显示修改后的
cv.imshow('resize_img',resize_img)
#打印原图尺寸大小
print('未修改',img.shape)
#打印修改后的大小
print('修改后',resize_img.shape)
# cv.waitKey(0)
#只有输入q时候,退出
while True:
if ord('q') == cv.waitKey(0):
break
#释放内存 由于OpenCV底层是C++语言编写的 使用完内存必须释放
cv.destroyAllWindows()
案例4,绘制矩形,圆形

#导入cv模块
import cv2 as cv
#读取图片
img = cv.imread('face1.jpg')
#左上角的坐标是(x,y) 矩形的宽高和高度(w,h)
x,y,w,h=100,100,100,100
#绘制矩形
cv.rectangle(img,(x,y,x+w,y+h),color=(0,0,255),thickness=1) #color=BGR
#绘制圆形 center为圆点坐标 radius为半径
x,y,r=200,200,100
cv.circle(img,center=(x,y),radius=r,color=(255,0,0),thickness=2)
#显示
cv.imshow('re_img',img)
# cv.waitKey(0)
#只有输入q时候,退出
while True:
if ord('q') == cv.waitKey(0):
break
#释放内存 由于OpenCV底层是C++语言编写的 使用完内存必须释放
cv.destroyAllWindows()
案例5,检测人脸

#导入cv模块
import cv2 as cv
#检测函数
def face_detect_demo():
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
face_detect = cv.CascadeClassifier('D:/soft/opencv/sources/data/haarcascades/haarcascade_frontalface_default.xml')
face = face_detect.detectMultiScale(gray,1.1,5) #限制最小最大宽高 ,0,(100,100),(300,300)
for x,y,w,h in face:
cv.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)
cv.imshow('result',img)
#读取图片
img = cv.imread('face1.jpg')
#检测函数
face_detect_demo()
# cv.waitKey(0)
#只有输入q时候,退出
while True:
if ord('q') == cv.waitKey(0):
break
#释放内存 由于OpenCV底层是C++语言编写的 使用完内存必须释放
cv.destroyAllWindows()
案例6,读取摄像头

#导入cv模块
import cv2 as cv
#检测函数
def face_detect_demo(img):
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
face_detect = cv.CascadeClassifier('D:/Program Files/opencv/sources/data/haarcascades/haarcascade_frontalface_alt2.xml')
face = face_detect.detectMultiScale(gray,1.1,5) #限制最小最大宽高 ,0,(100,100),(300,300)
for x,y,w,h in face:
cv.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)
cv.imshow('result',img)
#读取摄像头
cap = cv.VideoCapture(0)
# cap = cv.VideoCapture('1.mp4') #读视频
#循环
while True:
flag,frame=cap.read()
if not flag:
break
face_detect_demo(frame)
#按q退出
if ord('q') == cv.waitKey(0):
break
#释放内存 由于OpenCV底层是C++语言编写的 使用完内存必须释放
cv.destroyAllWindows()
#释放摄像头
cap.release()
案例7,保存摄像头图片

#导入cv模块
import cv2
#读取摄像头
cap = cv2.VideoCapture(0)
falg=1
num=1
while(cap.isOpened()):#检测是否开启状态
ret_flag,Vshow=cap.read()#得到每一帆图片
cv2.imshow('Capture_Test',Vshow)
k=cv2.waitKey(1) & 0xff
if k==ord('s'):#保存
cv2.imwrite('data/'+str(num)+'.name.jpg',Vshow)
msg="Success to save data/"+str(num)+".name.jpg"
print(msg)
print("-----------------")
num +=1
if k==ord(' '):#退出
break;
#释放摄像头
cap.release()
#释放内存 由于OpenCV底层是C++语言编写的 使用完内存必须释放
cv.destroyAllWindows()
案例8,生成人脸数据

import os
import cv2
from PIL import Image
import numpy as np
def getImageAndLabels(path):
#储存人脸数据
facesSamples=[]
#储存姓名数据
ids=[]
#储存图片信息
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]
#加载分类器
face_detector = cv2.CascadeClassifier('D:/Program Files/opencv/sources/data/haarcascades/haarcascade_frontalface_alt2.xml')
#遍历列表中的图片
for imagePath in imagePaths:
#打开图片,灰度化PIL有九种不同的模式:1,L,P,RGB,RGBA,CMYK,YCbCr,I,F
PIL_img = Image.open(imagePath).convert('L')
#将图像转化为数组,以黑白深浅
img_numpy = np.array(PIL_img,'uint8')
#获取图片人脸特征
faces = face_detector.detectMultiScale(img_numpy)
#获取每一张图片的id和姓名
id = int(os.path.split(imagePath)[1].split('.')[0])
#预防无面容照片
for x,y,w,h in faces:
ids.append(id)
facesSamples.append(img_numpy[y:y+h,x:x+w])
#打印面部特征和id
print('id',id)
print('fs:',facesSamples)
return facesSamples,ids
if __name__ == '__main__':
#图片路径
path = './data/' # data目录里图片为 1.wo.jpg 1为ID索引,wo为查到对应的值,改变值后查找后值也跟着改变
#获取图像数组和id标签数组和姓名
faces,ids=getImageAndLabels(path)
#加载识别器
recognizer = cv2.face.LBPHFaceRecognizer_create()
#训练
recognizer.train(faces,np.array(ids))
#保存文件
recognizer.write('tupian.yml')
案例9,识别人脸,通过摄像头或图片或视频

import cv2
import os
#加载训练数据文件
recogizer = cv2.face.LBPHFaceRecognizer_create()
#加载数据
recogizer.read('tupian.yml')
#名称
names=[]
#报警全局变量
warningtime = 0
#准备识别的图片
def face_detect_demo(img):
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#转换为灰度
face_detector=cv2.CascadeClassifier('D:/Program Files/opencv/sources/data/haarcascades/haarcascade_frontalface_alt2.xml')
face=face_detector.detectMultiScale(gray)
for x,y,w,h in face:
cv2.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)
cv2.circle(img,center=(x+w//2,y+h//2),radius=w//2,color=(0,255,0),thickness=1)
# 人脸识别
ids, confidence = recogizer.predict(gray[y:y + h, x:x + w])
if confidence > 80:
global warningtime
warningtime += 1
if warningtime > 100:
# warning()
warningtime = 0
cv2.putText(img, 'unkonw', (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
print("no")
else:
cv2.putText(img,str(names[ids-1]), (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
print("yes "+str(names[ids-1]))
cv2.imshow('result',img)
#名字标签
def name():
path = './data/'
# names = []
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]
for imagePath in imagePaths:
name = str(os.path.split(imagePath)[1].split('.',2)[1])
names.append(name)
#加载视频
# cap = cv2.VideoCapture(0) #摄像头
# cap=cv2.VideoCapture('1.mp4')
cap=cv2.VideoCapture('face1.jpg')
cap=cv2.VideoCapture('./data/1.xx.jpg')
name()
while True:
flag,frame=cap.read()
if not flag:
break
face_detect_demo(frame)
if ord(' ') == cv2.waitKey(10):
break
#释放内存+视频
cv2.destroyAllWindows()
cap.release()
案例10,通过IIS运行python
人脸识别案例>>

import cv2
import os
import cgi
print("Content-Type: text/html;charset=utf-8\n")
# 创建CGI处理程序的实例
form = cgi.FieldStorage()
# 从输入表单获取参数
imgName = form.getvalue('img')
# print("imgName="+imgName)
#加载训练数据文件
recogizer = cv2.face.LBPHFaceRecognizer_create()
#加载数据
recogizer.read('D:/work/xiyueta/tool/face/tupian.yml')
#名称
names=[]
#报警全局变量
warningtime = 0
#准备识别的图片
def face_detect_demo(img):
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#转换为灰度
face_detector=cv2.CascadeClassifier('D:/Program Files/opencv/sources/data/haarcascades/haarcascade_frontalface_alt2.xml')
face=face_detector.detectMultiScale(gray)
for x,y,w,h in face:
cv2.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)
cv2.circle(img,center=(x+w//2,y+h//2),radius=w//2,color=(0,255,0),thickness=1)
# 人脸识别
ids, confidence = recogizer.predict(gray[y:y + h, x:x + w])
if confidence > 80:
global warningtime
warningtime += 1
if warningtime > 100:
# warning()
warningtime = 0
cv2.putText(img, 'unkonw', (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
# print("no")
else:
cv2.putText(img,str(names[ids-1]), (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
print(str(names[ids-1]))
cv2.imshow('result',img)
#名字标签
def name():
path = 'D:/work/xiyueta/tool/face/data/'
# names = []
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]
for imagePath in imagePaths:
name = str(os.path.split(imagePath)[1].split('.',2)[1])
names.append(name)
cap=cv2.VideoCapture('D:/work/xiyueta/tool/face/upload/'+imgName)
name()
while True:
flag,frame=cap.read()
if not flag:
break
face_detect_demo(frame)
if ord(' ') == cv2.waitKey(10):
break
在iis上运行Python,安装配置步骤
1、打开iis >> 选择ISAPI和CGI限制 >> 添加 >> 输入 C:\python\python.exe %s %s 描述输入 python 勾选(允许执行扩展路径)
2、打开iis >> 选择处理程序映射 >> 添加脚本映射 >> 请求路径 输入 *.py , 可执行文件 输入 C:\python\python.exe %s %s , 名称输入 python
Requests是简单易用的Python HTTP库。
win+r >> 窗口输入cmd >> 输入 pip install requests
第二种: win+r >> 窗口输入cmd >> 输入 pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple
查看案例>>
 C:\python\python.exe %s %s 描述输入 python 勾选(允许执行扩展路径)
C:\python\python.exe %s %s 描述输入 python 勾选(允许执行扩展路径)

 请求路径 输入 *.py , 可执行文件 输入 C:\python\python.exe %s %s , 名称输入 python
请求路径 输入 *.py , 可执行文件 输入 C:\python\python.exe %s %s , 名称输入 python

import cgi
import socket
# 获取URL中的参数
params = cgi.FieldStorage()
# 获取参数值
url = params.getvalue('url')
# 获取当前用户的IP地址
ip = socket.gethostbyname(socket.gethostname())
# 提取字符串中的前8位
result = ip[:8]
print("Content-type:text/html;charset=gb2312\r\n")
print("<html>")
print("<head><title>python在iis里运行网页案例</title></head>")
print("<body>")
print("<h2>python在iis里运行网页案例</h2>")
print("ip="+ip)
if url:
print("<br>url="+url)
一个简单的python案例,以网页方式打开,并且可以正确显示中文汉字
查看案例>>
import cgi
print("Content-type:text/html;charset=gb2312\r\n")
print("<html>")
print("<head><title>Hello World - CGITest</title></head>")
print("<body>")
print("<h2>Hello World! 你好,世界!</h2>")
print("</body>")
print("</html>")
输入网址:http://www.dependencywalker.com/选择对应版本
Dependency Walker能分析出EXE所依赖的DLL和函数,各模块之间的关系,对开发和分析有很大的帮助。


PyAutoGUI是一个纯Python的GUI自动化工具,通过它可以让程序自动控制鼠标和键盘的一系列操作来达到自动化测试的目的。
win+r >> 窗口输入cmd >> 输入 pip install pyautogui
第二种: win+r >> 窗口输入cmd >> 输入 pip install pyautogui -i https://pypi.tuna.tsinghua.edu.cn/simple
PyAutoGUI 简单案例
import pyautogui
# 移动鼠标
# pyautogui.moveTo(200,400,duration=2) #鼠标移动到指定的像素
# pyautogui.moveRel(200,500,duration=2) #鼠标按照当前点向右移动
# 获取鼠标位置
# print(pyautogui.position())
# 鼠标点击,默认左键
# pyautogui.click(100,100)
# # 单击左键
# pyautogui.click(100,100,button='left')
# # 单击右键
# pyautogui.click(100,300,button='right')
# # 单击中间
# pyautogui.click(100,300,button='middle')
# 双击左键
# pyautogui.doubleClick(10,10)
# # 双击右键
# pyautogui.rightClick(10,10)
# # 双击中键
# pyautogui.middleClick(10,10)
# 鼠标按下
# pyautogui.mouseDown()
# # 鼠标释放
# pyautogui.mouseUp()
# 控制鼠标拖动到指定坐标位置
# pyautogui.dragTo(100,300,duration=1)
# 按照方向拖动鼠标
# pyautogui.dragRel(100,300,duration=4)
# 鼠标滚动
# pyautogui.scroll(30000)
# 获取屏幕截图
# im = pyautogui.screenshot()
# im.save('screenshot.png')
# rgb = im.getpixel((100, 500)) #获取屏幕截图中指定坐标点的颜色
# print(rgb)
# match = pyautogui.pixelMatchesColor(500,500,(12,120,400)) #将指定坐标点的颜色和目标的颜色进行比对,返回布尔值
# print(match)
# 图像识别(一个)
# oneLocation = pyautogui.locateOnScreen('1.png')
# print(oneLocation)
# # 图像识别(多个)
# allLocation = pyautogui.locateAllOnScreen('1.png')
# print(list(allLocation))
# 按住 shift 按键,然后再按住 1 按键
# pyautogui.keyDown('shift')
# pyautogui.press('1')
# pyautogui.keyUp('shift')
# 直接输出内容 一个字符一个字符输出
# pyautogui.typewrite('python', 1)
# 弹出一个选择框
# way = pyautogui.confirm('领导,该走哪条路?', buttons=['农村路', '水路', '陆路'])
# print(way)
# 警告框
alert = pyautogui.alert(text='警告!敌军来袭!', title='警告框')
print(alert)
# 密码框
password = pyautogui.password('请输入密码')
print(password)
# 普通输入框
input = pyautogui.prompt('请输入指令:')
print(input)
import pyautogui
x=0
while x<50:
oneLocation = pyautogui.locateOnScreen('3.png',confidence=0.8)
print(oneLocation)
pyautogui.moveTo(oneLocation)
#鼠标点击
# pyautogui.click(oneLocation)
x=x+1
使用python和pdfkit库,编写一个简单的html转PDF脚本,即可将python中的HTML转换为PDF
win+r >> 窗口输入cmd >> 输入 pip install pdfkit
第二种: win+r >> 窗口输入cmd >> 输入 pip install pdfkit -i https://pypi.tuna.tsinghua.edu.cn/simple
wkhtmltopdf是一款非常流行的开源工具,用于将HTML网页转换成PDF或图片等格式。它采用WebKit渲染引擎,支持CSS3,JavaScript和HTML5。 >> 网址:https://wkhtmltopdf.org/downloads.html >> 选择对应的操作系统版本下载

#获得pdf文件全部内容,并替换指定内容
import fitz
# 打开 PDF 文件
with fitz.open('1.pdf') as pdf_file:
# 遍历每个页面,读取页面的文本内容
for page in pdf_file:
# 读取页面的文本内容
text = page.get_text()
text=text.replace('\n', '').replace(' ','')
# 将文本写入文件
with open('1.txt', 'a', encoding='utf-8') as f:
f.write(text)
f.write("\n\n\n")
# 读取文件内容
with open('1.txt', 'r', encoding='utf-8') as f:
file_data = f.read()
# 替换文本
new_data = file_data.replace('查找内容', '替换内容')
# 将修改后的内容写入文件
with open('1.txt', 'w', encoding='utf-8') as f:
f.write(new_data)
#html生成pdf 成功
import pdfkit
options = {
'page-size': 'A4',
'margin-top': '0mm',
'margin-right': '0mm',
'margin-bottom': '0mm',
'margin-left': '0mm',
'encoding': "UTF-8",
'no-outline': None
}
# 指定wkhtmltopdf的安装路径
config = pdfkit.configuration(wkhtmltopdf ='C:/Program Files/wkhtmltopdf/bin/wkhtmltopdf.exe')
# 将HTML文件转换为PDF
pdfkit.from_file('example.html', 'example.pdf', configuration=config, options=options)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
* {
font-family: 'Microsoft Yahei';
line-height: 1.8em;
color: #555;
font-size: 1.8em;
}
body{margin:0;padding:2em 1em;}
</style>
</head>
<body>
html里的内容字符
</body></html>
PIL对图像处理,如加法运算,减法运算,变暗运算,变亮运算,变亮运算,叠加运算,反色运算,比较运算(图片找茬用这个找)
from PIL import Image,ImageChops
#打开图片
img1=Image.open('a1.bmp')
img2=Image.open('b1.bmp')
#对两张图片进行算术加法运算
# ImageChops.add(img1,img2).show()
#对两张图片进行算术减法运算
# ImageChops.subtract(img1,img2).show()
#对两张图片进行算术变暗运算
# ImageChops.darker(img1,img2).show()
#对两张图片进行算术变亮运算
# ImageChops.lighter(img1,img2).show()
#对两张图片进行算术变亮运算
# ImageChops.lighter(img1,img2).show()
#对两张图片进行算术叠加运算
# ImageChops.multiply(img1,img2).show()
#对两张图片进行算术屏幕运算
# ImageChops.screen(img1,img2).show()
#对两张图片进行算术反色运算
# ImageChops.invert(img1).show()
#对两张图片进行算术比较运算
ImageChops.difference(img1,img2).show() #图片找茬可以用这种方法来查找
import time
import os
from PIL import Image,ImageChops
def convert_images_to_gif(directory):
file_list = os.listdir(directory)
jpg_files = [file for file in file_list if file.endswith(".jpg")]
if jpg_files:
images = []
gif_file = os.path.join(directory, "PIC3.jpg")
if not os.path.exists(gif_file): # 检查 GIF 文件是否已存在
for jpg_file in jpg_files:
jpg_path = os.path.join(directory, jpg_file)
if jpg_file=="PIC1.jpg" or jpg_file=="PIC2.jpg":
images.append(jpg_path)
if jpg_file=="PIC1.jpg":
img1=Image.open(directory + jpg_file)
# print("img1",img1)
elif jpg_file=="PIC2.jpg":
img2=Image.open(directory + jpg_file)
# print("img2",img2)
img=ImageChops.difference(img1,img2) #图片找茬可以用这种方法来查找
img.save(directory + "PIC3.jpg") #将图片保存为haha.jpg
gif_file = os.path.join(directory, "PIC4.gif")
# 在这里添加将图片转换为gif的代码,具体转换方法可以使用Pillow库或者imageio库
# 这里只提供一个简单的示例,需要自行安装对应库并调整代码
# 如需使用Pillow库,可以使用以下代码:
Image.open(images[0]).save(gif_file, save_all=True, append_images=[Image.open(img) for img in images[1:]], duration=300, loop=0)
print("已成功将图像转换!")
else:
print("图片文件已存在,正在跳过转换。")
else:
print("在目录中找不到JPG文件。")
def timer():
while True:
# 指定目录
directory = "./help/"
if os.path.isdir(directory):
convert_images_to_gif(directory)
else:
print("无效目录!")
time.sleep(2) # 休眠3秒
timer()
ddddocr是一种将印刷体或手写文本转换为可编辑、可搜索和可处理的电子文本的技术。它通过图像处理和模式识别等技术,将图像中的文字转化为计算机可识别的字符编码。
pip install ddddocr
第二种: win+r >> 窗口输入cmd >> 输入 pip install ddddocr -i https://pypi.tuna.tsinghua.edu.cn/simple
pip show ddddocr 查看版本等信息
报错解决:版本问题



在使用ddddocr时报下面错误,解决方法:
^^^^^^^^^^^^^^^^^^^^^^
File "C:\python\Lib\site-packages\ddddocr\__init__.py", line 466, in classific
ation
image = image.resize((int(image.size[0] * (64 / image.size[1])), 64), Image.
ANTIALIAS).convert('L')
^^^^^^
^^^^^^^^^
原来是在pillow的10.0.0版本中,ANTIALIAS方法被删除了,使用新的方法即可:
Image.LANCZOS 旧版
Image.Resampling.LANCZOS 新版本 或 Image.LANCZOS
C:\python\Lib\site-packages\ddddocr\__init__.py 文件里修改:
# image = image.resize((int(image.size[0] * (64 / image.size[1])), 64), Image.ANTIALIAS).convert('L')
image = image.resize((int(image.size[0] * (64 / image.size[1])), 64), Image.LANCZOS).convert('L')
import ddddocr,time
ocr=ddddocr.DdddOcr()
with open('yzm.png','rb') as files:
yu=files.read()
time.sleep(1)
ui=ocr.classification(yu)
print(ui)
from flask import Flask,request
import ddddocr,time
app = Flask(__name__)
@app.route("/")
def helloword():
ocr=ddddocr.DdddOcr()
with open('yzm.png','rb') as files:
yu=files.read()
time.sleep(1)
ui=ocr.classification(yu)
print(ui)
return '<h1>hello world!</h1>ui=' + ui
if __name__ == '__main__':
app.run(host="192.168.2.6",port=90,debug=True)
PySimpleGUI是基于Python的图形界面开发工具,相较于Python自带的图形界面开发库Tkinter,第三方图形界面开发工具PyQT、WxPython等,其具有基础要求低、代码量少、修改方便
github地址:https://github.com/PySimpleGUI/PySimpleGUI
需要安装的库
pip install PySimpleGUI -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pdf2docx -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install PyPDF2 python-docx -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install fpdf python-docx -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install reportlab python-docx -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install docx2pdf python-docx -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install comtypes -i https://pypi.tuna.tsinghua.edu.cn/simple

import comtypes.client
from pdf2docx import Converter
import PySimpleGUI as sg
from PyPDF2 import PdfReader
from docx import Document
from fpdf import FPDF
# pdf转word
def pdf_to_word(file_path):
file_name = file_path.split('.')[0]
doc_file = f'{file_name}.docx'
#我添加的,之前旧版不可用,不可为什么
pdf_reader = PdfReader(file_path)
doc = Document()
for page in pdf_reader.pages:
text = page.extract_text()
doc.add_paragraph(text)
doc.save(doc_file)
return doc_file
# pdf转txt
def pdf_to_txt(file_path):
file_name = file_path.split('.')[0]
doc_file = f'{file_name}.txt'
pdf_reader = PdfReader(file_path)
with open(doc_file, 'w', encoding='utf-8') as txt_file:
for page in pdf_reader.pages:
text = page.extract_text()
txt_file.write(text)
return doc_file
# word转pdf
def word2pdf(file_path):
word = comtypes.client.CreateObject('Word.Application')
word.Visible = 0
file_name = file_path.split('.')[0]
pdf_file = f'{file_name}.pdf'
w2p = word.Documents.Open(file_path)
w2p.SaveAs(pdf_file, FileFormat=17)
w2p.Close()
return pdf_file
# txt转pdf
def txt_to_pdf(txt_path):
pdf = FPDF()
pdf.add_page()
file_name = txt_path.split('.')[0]
pdf_path = f'{file_name}.pdf'
with open(txt_path, 'r', encoding='utf-8') as txt_file:
contents = txt_file.read()
pdf.multi_cell(0, 10, contents)
pdf.output(pdf_path)
# doc转pdf
def docx_to_pdf(docx_path):
document = Document(docx_path)
paragraphs = document.paragraphs
file_name = docx_path.split('.')[0]
pdf_path = f'{file_name}.pdf'
pdf = FPDF()
pdf.add_page()
for para in paragraphs:
pdf.multi_cell(0, 10, para.text)
pdf.output(pdf_path)
def main():
# 选择主题
sg.theme('LightBlue5')
layout = [
[sg.Text('PDF与WORD转换小工具', font=('微软雅黑', 12)),
sg.Text('', key='filename', size=(50, 1), font=('微软雅黑', 10), text_color='blue')],
[sg.Output(size=(80, 10), font=('微软雅黑', 10))],
[sg.FilesBrowse('选择文件', key='file', target='filename'), sg.Button('pdf转word'), sg.Button('pdf转txt'), sg.Button('word转pdf'), sg.Button('txt转pdf'),
sg.Button('退出')]]
# 创建窗口
window = sg.Window("PDF与WORD转换小工具", layout, font=("微软雅黑", 15), default_element_size=(50, 1))
# 事件循环
while True:
# 窗口的读取,有两个返回值(1.事件;2.值)
event, values = window.read()
print(event, values)
if event == 'pdf转word':
if values['file'] and values['file'].split('.')[1] == 'pdf':
pdf_filename = pdf_to_word(values['file'])
print('pdf文件个数 :1')
print('\n' + '转换成功!' + '\n')
print('文件保存位置:', pdf_filename)
elif values['file'] and values['file'].split(';')[0].split('.')[1] == 'pdf':
print('pdf文件个数 :{}'.format(len(values['file'].split(';'))))
for f in values['file'].split(';'):
pdf_filename = pdf_to_word(f)
print('\n' + '转换成功!' + '\n')
print('文件保存位置:', pdf_filename)
else:
print('请选择pdf格式的文件哦!')
elif event == 'pdf转txt':
if values['file'] and values['file'].split('.')[1] == 'pdf':
pdf_filename = pdf_to_txt(values['file'])
print('pdf文件个数 :1')
print('\n' + '转换成功!' + '\n')
print('文件保存位置:', pdf_filename)
elif values['file'] and values['file'].split(';')[0].split('.')[1] == 'pdf':
print('pdf文件个数 :{}'.format(len(values['file'].split(';'))))
for f in values['file'].split(';'):
pdf_filename = pdf_to_txt(f)
print('\n' + '转换成功!' + '\n')
print('文件保存位置:', pdf_filename)
else:
print('请选择pdf格式的文件哦!')
elif event == 'word转pdf':
if values['file'] and values['file'].split('.')[1] == 'docx':
word_filename = word2pdf(values['file'])
print('word文件个数 :1')
print('\n' + '转换成功!' + '\n')
print('文件保存位置:', word_filename)
elif values['file'] and values['file'].split(';')[0].split('.')[1] == 'docx':
print('word文件个数 :{}'.format(len(values['file'].split(';'))))
for f in values['file'].split(';'):
filename = word2pdf(f)
print('\n' + '转换成功!' + '\n')
print('文件保存位置:', filename)
else:
print('请选择docx格式的文件哦!')
elif event == 'txt转pdf':
if values['file'] and values['file'].split('.')[1] == 'txt':
word_filename = txt_to_pdf(values['file'])
print('txt文件个数 :1')
print('\n' + '转换成功!' + '\n')
print('文件保存位置:', word_filename)
elif values['file'] and values['file'].split(';')[0].split('.')[1] == 'txt':
print('txt文件个数 :{}'.format(len(values['file'].split(';'))))
for f in values['file'].split(';'):
filename = txt_to_pdf(f)
print('\n' + '转换成功!' + '\n')
print('文件保存位置:', filename)
else:
print('请选择txt格式的文件哦!')
elif event in (None, '退出'):
break
window.close()
if __name__ == '__main__':
main()
pip install Flask Flask 是一个基于 Python 的轻量级 Web 应用框架。它使用 Werkzeug 作为 HTTP 工具包和 Jinja 2 作为模板引擎。 第二种: win+r >> 窗口输入cmd >> 输入 pip install Flask -i https://pypi.tuna.tsinghua.edu.cn/simple
注意:当开启flask Web服务器后,当改变文件程序内容,flash会自动更新文件程序

from flask import Flask,request
app = Flask(__name__)
@app.route("/")
def helloword():
return '<h1>hello world!</h1>'
if __name__ == '__main__':
app.run(host="192.168.2.6",port=90,debug=True)
Matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形。
安装 pip install matplotlib
第二种: win+r >> 窗口输入cmd >> 输入 pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple

import matplotlib.pyplot as plt
plt.figure(figsize=(10,10),dpi=100)
plt.plot([1,2,3,4,5,6,7],[17,17,18,15,11,11,13])
plt.show()
PyZbar是一个Python库,用于解码二维码和条形码。它基于ZBar库,是一个开源的C++库,可以解码多种格式的二维码和条形码,如QR Code、Data Matrix、Aztec Code等。PyZbar提供了Python的绑定,使得在Python中使用ZBar库变得更加简单。 安装 pip install pyzbar
第二种: win+r >> 窗口输入cmd >> 输入 pip install pyzbar -i https://pypi.tuna.tsinghua.edu.cn/simple
import matplotlib.pyplot as plt
plt.figure(figsize=(10,10),dpi=100)
plt.plot([1,2,3,4,5,6,7],[17,17,18,15,11,11,13])
plt.show()
Pandas是一个Python数据分析库,提供了高性能、易用的数据结构和数据分析工具。它可以用来处理数据表格、时间序列、数据可视化等。Pandas是基于NumPy的,它提供了Series和DataFrame两种数据结构,其中Series类似于一个一维数组,DataFrame类似于一个二维的表格。
安装 pip install pandas
第二种: win+r >> 窗口输入cmd >> 输入 pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
import pandas as pd
my_list=[('join',25,'male'),('lisa',30,'female'),('david',18,'male')]
df=pd.DataFrame(my_list,columns=['Name','Age','gender'])
print(df)
使用python对图片进行压缩
from PIL import Image
def compress_image(input_path, output_path, quality=50):
# 打开图片
img = Image.open(input_path)
# 压缩图片
img.save(output_path, quality=quality)
# 示例:将input.jpg压缩为output.jpg,压缩质量为50%
compress_image('input.jpg', 'output.jpg', quality=50)
import os
from PIL import Image
def process_png(input_path, output_path, max_width=200, quality=85):
with Image.open(input_path) as img:
# 获取原始宽度和高度
width, height = img.size
# 如果宽度大于max_width,则调整大小
if width > max_width:
# 计算调整后的高度,保持宽高比
new_height = int((max_width / width) * height)
img = img.resize((max_width, new_height), Image.LANCZOS)
# 保存处理后的图片
img.save(output_path, 'PNG', optimize=True, quality=quality)
def batch_process_png(src_dir, dist_dir, max_width=200, quality=85):
# 确保输出目录存在
if not os.path.exists(dist_dir):
os.makedirs(dist_dir)
# 遍历src目录
for filename in os.listdir(src_dir):
if filename.lower().endswith('.png'):
input_path = os.path.join(src_dir, filename)
output_path = os.path.join(dist_dir, filename)
# 处理PNG文件
process_png(input_path, output_path, max_width, quality)
print(f"Processed: {filename}")
# 使用示例
src_directory = 'src'
dist_directory = 'dist'
max_width = 200 # 最大宽度
compression_quality = 85 # 压缩质量,范围是1-95
batch_process_png(src_directory, dist_directory, max_width, compression_quality)
print("Processing completed!")
pypinyin汉字转拼音
win+r >> 窗口输入cmd >> 输入 pip install pypinyin
第二种: win+r >> 窗口输入cmd >> 输入 pip install pypinyin -i https://pypi.tuna.tsinghua.edu.cn/simple
from pypinyin import pinyin, lazy_pinyin, Style
def hanzi_to_pinyin(hanzi):
# 使用默认风格的拼音
pinyin_list = pinyin(hanzi)
# 将拼音列表转换为字符串
pinyin_str = ''.join([item[0] for item in pinyin_list])
return pinyin_str
def hanzi_to_pinyin_with_tone(hanzi):
# 带声调的拼音
pinyin_list = pinyin(hanzi, style=Style.TONE)
pinyin_str = ''.join([item[0] for item in pinyin_list])
return pinyin_str
def hanzi_to_pinyin_lazy(hanzi):
# 使用lazy_pinyin函数,它不考虑多音字,只返回每个汉字第一个拼音
pinyin_list = lazy_pinyin(hanzi)
pinyin_str = ''.join(pinyin_list)
return pinyin_str
# 示例:
hanzi = "你好,世界!"
print("默认风格的拼音:", hanzi_to_pinyin(hanzi))
print("带声调的拼音:", hanzi_to_pinyin_with_tone(hanzi))
print("不考虑多音字的拼音:", hanzi_to_pinyin_lazy(hanzi))
Selenium 是一个用于Web应用程序测试的工具集。它直接运行在浏览器中,模拟用户的真实操作,如点击、输入文本、获取页面数据等。Selenium 支持多种浏览器(包括Chrome、Firefox、Safari等)和多种编程语言(如Java、Python、C#等)。
selenium安装: cmd >> pip install selenium
webdriver-manager安装: cmd >> pip install webdriver-manager -i https://pypi.tuna.tsinghua.edu.cn/simple

from selenium import webdriver
from selenium.webdriver.common.by import By
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
# 获取并打印网页标题
print(driver.title)
time.sleep(16)
driver.close()
pytest 是一个成熟的 Python 测试框架,它使得编写小型和大型测试变得既简单又灵活。一个简单案例
pytest安装: cmd >> pip install pytest -i https://pypi.tuna.tsinghua.edu.cn/simple
from selenium import webdriver
from selenium.webdriver.common.by import By
def test_baidu():
driver = webdriver.Chrome()
# driver.maximize_window()
driver.get("https://www.baidu.com/")
title = driver.title
url = driver.current_url
text = driver.find_element(By.CSS_SELECTOR,'a[href="http://news.baidu.com"]').text
button_text = driver.find_element(By.ID,'su').accessible_name
assert title == "百度一下,你就知道"
assert url == "https://www.baidu.com/"
assert text == "新闻"
assert button_text == "百度一下"
xiyueta.js库在python里使用方法python文件内容
下载案例源码>>
# 导入执行JS代码模块 <需要安装>
import execjs #安装 pip install PyExecJS
f=open('5.js', encoding='utf-8').read()
js_code = execjs.compile(f)
result=js_code.call('load',"hello world!xiyueta.js")
# print(result)
print("msg:", result["msg"])
print("obj:", result["obj"] )
print("obj:", result["obj"]['length'] )
print("html:", result["html"] )
txt = js_code.call('test','hello world!','div')
print(txt)
const xiyueta = require('xiyueta') //安装 npm install xiyueta
function load(html,selector){
xiyueta.load(html)
xiyueta("*").css("color","red")
xiyueta("span").htmlwrap("<p>qq:313801120</p>")
return { obj: xiyueta("*"), html:xiyueta.html(), msg:"test" };
}
function test(html,selector){
xiyueta.load(html)
xiyueta('div').text('xiyueta.com');
return xiyueta.html();
} 采集网页案例
import cgi
import requests
print("Content-type:text/html;charset=gb2312\r\n")
# 创建一个会话(session)对象
session = requests.Session()
# 在会话对象中设置请求头,启用压缩
session.headers.update({'Accept-Encoding': 'gzip, deflate'})
# 发送GET请求
response = session.get('https://xiyeuta.com/')
# 打印响应内容
print(response.text)
请求参数不乱码
import cgi
import cgi
print("Content-type:text/html;charset=gb2312\r\n")
# 获取用户传过来的值
form = cgi.FieldStorage()
token = form.getvalue('token')
msg = form.getvalue('msg')
# 打印调试信息
print(f"Token: {token}, Msg: {msg}")
收集一些python基础案例

for i in range(0,10): #range=范围
print("i = %d" %i)

#设置class1和class2两个列表
class1=['Joan','Bill','Niki',"Mark","Mark"]
class2=['Tom','Linda','Bill']
#循环遍历class1,其中每个元素都与class2中的元素做比较
for name1 in class1:
for name2 in class2:
if name1==name2:#如果相同
print(name1)#将该元素打印
python连接sqlserver操作增删改查

import cgi
import pyodbc
print("Content-type:text/html;charset=gb2312\r\n")
print("<html>")
print("<head><title>python连接sqlserver操作增删改查</title></head>")
print("<body>")
# 连接字符串,包含连接数据库所需的信息
conn_str = (
r'DRIVER={SQL Server};'
r'SERVER=localhost;'
r'DATABASE=webdata;'
r'UID=sa;'
r'PWD=sapass;'
)
# 连接到数据库
conn = pyodbc.connect(conn_str)
# 创建游标
cursor = conn.cursor()
# 获取URL中的参数
params = cgi.FieldStorage()
# 获取参数值
act = params.getvalue('act')
id = params.getvalue('id')
bodycontent = params.getvalue('bodycontent')
# form = cgi.FieldStorage()
# # 获取 title 字段的值
# bodycontent = form.getvalue('bodycontent')
if act:
if act=="submit":
if bodycontent:
# 插入数据
sql = "INSERT INTO xy_xiyueta (bodycontent) VALUES ('"+str(bodycontent)+"')"
if id:
sql = "UPDATE xy_xiyueta SET bodycontent = '"+str(bodycontent)+"' WHERE id="+str(id)
print("sql="+sql+"<br>")
cursor.execute(sql)
# 提交事务
conn.commit()
else:
print("请输入内容")
elif act=="del":
if id:
sql = "DELETE FROM xy_xiyueta WHERE id = "+str(id)
cursor.execute(sql)
# 提交事务
conn.commit()
elif act=="edit":
if id:
sql = "SELECT * FROM xy_xiyueta WHERE id = "+str(id)
# print(sql)
cursor.execute(sql)
# 读取查询结果
for row in cursor:
bodycontent=row.bodycontent
# 执行SQL查询
cursor.execute('SELECT * FROM xy_xiyueta')
print("<a href='?act=showadd'>添加</a> | ")
print("<hr><br>")
if act=="showadd" or act=="edit":
if not bodycontent:
bodycontent=""
if not id:
id=""
print('<form id="form1" name="form1" method="post" action="?act=submit&id='+str(id)+'"> 内容: <input type="text" value="'+str(bodycontent)+'" name="bodycontent" id="bodycontent" /> <input type="submit" name="button" id="button" value="提交" /></form>')
# 读取查询结果
for row in cursor:
print(row.bodycontent,row.createtime,"<a href='?act=del&id="+str(row.id)+"' onclick=\"if(confirm('确认删除?')==false)return false;\">删除</a> | <a href='?act=edit&id="+str(row.id)+"'>修改</a><br>")
# 关闭游标和连接
cursor.close()
conn.close()
pyinstaller打包生成界面软件 安装打包库
pip install pyinstaller -i https://mirrors.aliyun.com/pypi/simple/
打包
pyinstaller --windowed --onefile 3.py
v0里输入下面提示词获得代码:
python写个界面,界面里有两个按钮,一个加按钮,点击加1,一个减按钮,点击减1,并显示数字

import tkinter as tk
from tkinter import ttk
class EnhancedCounterApp:
def __init__(self, master):
self.master = master
self.master.title("Enhanced Counter")
# Set window size and position it in the center of the screen
window_width = 400
window_height = 300
screen_width = master.winfo_screenwidth()
screen_height = master.winfo_screenheight()
center_x = int(screen_width/2 - window_width/2)
center_y = int(screen_height/2 - window_height/2)
self.master.geometry(f'{window_width}x{window_height}+{center_x}+{center_y}')
# Set minimum window size
self.master.minsize(300, 200)
# Configure the main window grid
self.master.columnconfigure(0, weight=1)
self.master.rowconfigure(0, weight=1)
# Create main frame
main_frame = ttk.Frame(master, padding="20")
main_frame.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
# Initialize counter
self.count = 0
# Style configuration
style = ttk.Style()
style.configure('Large.TLabel', font=('Arial', 48, 'bold'))
style.configure('Counter.TButton', font=('Arial', 16))
# Create and place the label
self.label = ttk.Label(main_frame, text="0", style='Large.TLabel')
self.label.grid(row=0, column=0, columnspan=2, pady=30)
# Create button frame
button_frame = ttk.Frame(main_frame)
button_frame.grid(row=1, column=0, columnspan=2, pady=20)
# Create and place the buttons
self.add_button = ttk.Button(
button_frame,
text="+",
command=self.increment,
style='Counter.TButton',
width=10
)
self.add_button.pack(side=tk.LEFT, padx=10)
self.subtract_button = ttk.Button(
button_frame,
text="-",
command=self.decrement,
style='Counter.TButton',
width=10
)
self.subtract_button.pack(side=tk.LEFT, padx=10)
# Add keyboard bindings
self.master.bind('<plus>', lambda e: self.increment())
self.master.bind('<minus>', lambda e: self.decrement())
self.master.bind('<Up>', lambda e: self.increment())
self.master.bind('<Down>', lambda e: self.decrement())
def increment(self):
self.count += 1
self.update_label()
def decrement(self):
self.count -= 1
self.update_label()
def update_label(self):
self.label.config(text=str(self.count))
def main():
root = tk.Tk()
root.configure(bg='white') # Set background color
app = EnhancedCounterApp(root)
root.mainloop()
if __name__ == "__main__":
main()
如果版本高于 114: https://googlechromelabs.github.io/chrome-for-testing/known-good-versions-with-downloads.json
https://googlechromelabs.github.io/chrome-for-testing/


RapidOCR 是一个基于 PaddleOCR(百度飞桨)模型进行优化的开源项目。它的核心目标是轻量化和跨平台
安装:pip install onnxruntime rapidocr_onnxruntime
更多: python -m pip list 查看安装组件
from rapidocr_onnxruntime import RapidOCR
# 初始化引擎
engine = RapidOCR()
# 图片路径 (也可以是 numpy array 或 bytes)
img_path = 'test_image.jpg'
# 执行识别
# result 返回列表,elapse 返回耗时
result, elapse = engine(img_path)
print(result)Sherpa-ONNX 新一代离线语音识别工具,极速稳定且不挑硬件。
第一步安装:pip install sherpa-onnx numpy
第二步模型下载地址:https://github.com/k2-fsa/sherpa-onnx/releases/download/asr-models/sherpa-onnx-paraformer-zh-2023-09-14.tar.bz2
标点模型sherpa-onnx-punctuation-zh-cn-common-vad_realtime-vocab272727下载,把model.int8.onnx和tokens.json放到当前punc_model目录,下载地址 https://github.com/k2-fsa/sherpa-onnx/releases/download/punctuation-models/sherpa-onnx-punct-ct-transformer-zh-en-vocab272727-2024-04-12-int8.tar.bz2
 标点模型配置
标点模型配置

Edge-TTS。基于 Python 的一个开源工具,让你能够绕过复杂的 API 注册,直接“白嫖”微软 Edge 浏览器自带的顶级 AI 神经网络语音接口。
安装:pip install edge-tts
验证列表:edge-tts --list-voices
用法:edge-tts --text "你要读的文字" --write-media 结果.mp3
